机器学习模型可直接预测农药在植物根系的累积
新京报讯(记者 周怀宗)农作物累积是农业污染物从土壤进入人类食物链的重要途径。近日,记者从中国农科院植物保护研究所获悉,我科研人员首次利用机器学习模型直接预测植物根部从土壤中吸收累积农药等有机污染物的量,为农产品在产地环境化学污染的预测提供了新的工具和手段。
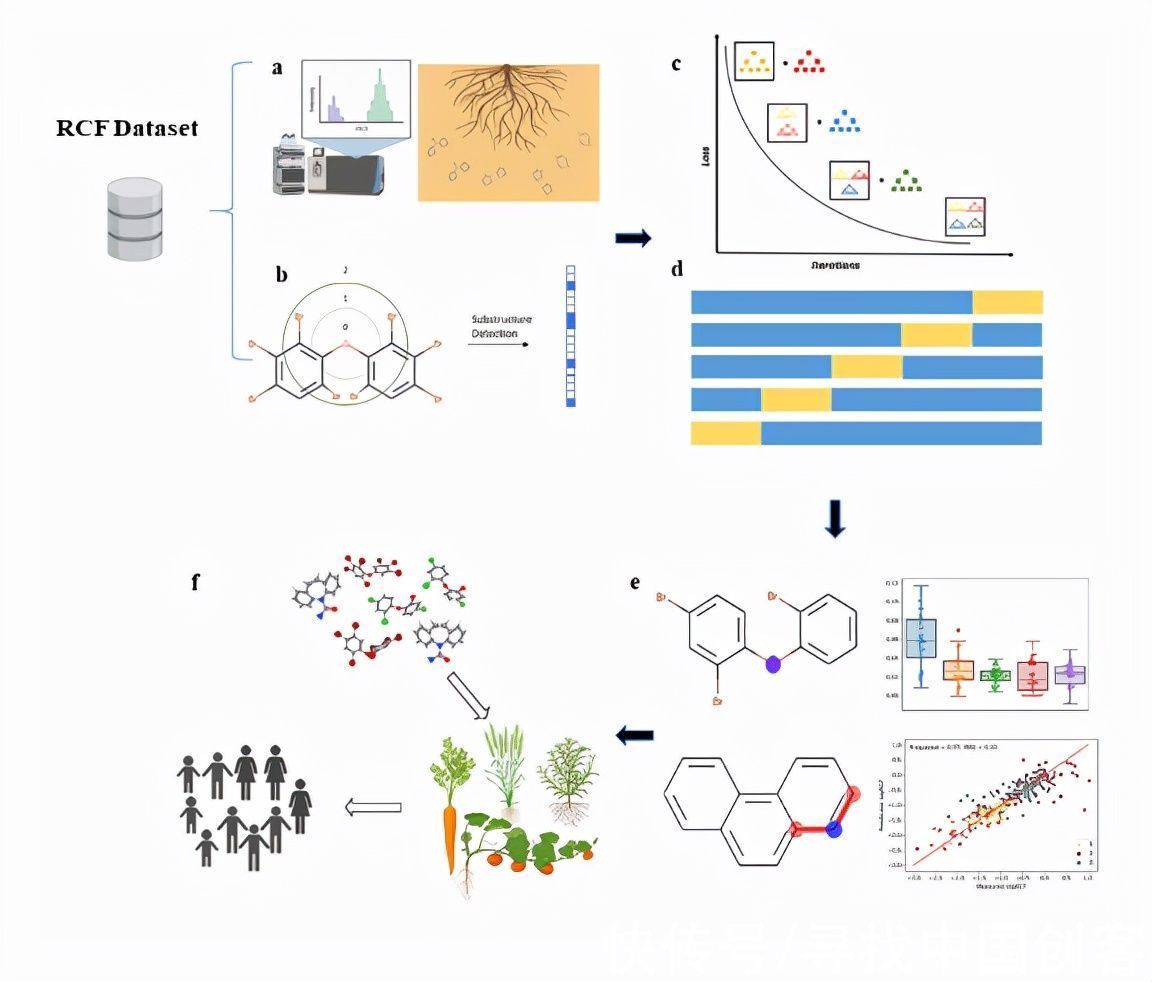
机器学习模型预测植物吸收累积农业污染物的示意流程图。中国农科院供图
据介绍,准确预测植物吸收和累积农业污染物对保障食品安全、产地修复和人类健康暴露评估具有重要的意义。然而,由于污染物-土壤-植物根系之间复杂的相互作用,建立稳健可靠的预测模型仍然具有很大挑战性。传统的线性预测模型难以预测污染物-土壤-植物间的非线性关系,导致预测值与实际值差异较大。
在此次研究中,科研人员对比了四种不同的机器学习算法,通过对341个数据点、72个化合物的数据集进行训练,预测植物根系富集值,证明了新构建的GBRT-ECFP模型为最优预测模型,并通过5倍交叉验证评估了预测性能,其中R2值为0.77,平均绝对误差(MAE)为0.22。此外,本研究解析了化学分子、土壤与植物特性之间的非线性关系。
研究成功利用机器学习作为新兴手段预测农田作物对农药等污染物的吸收累积,展现了预测工具的先进性和通用性,为未来新农药植物吸收潜能评估和农田农药污染安全评价提供新的可靠工具。
该研究得到了国家重点研发计划、青年英才计划等项目的资助。研究成果先后发表在《环境科学与技术(Environmental Science & Technology)》和《危害性材料学报(Journal of Hazardous Materials)》上。
新京报记者 周怀宗
编辑 唐峥 校对 陈荻雁
文章来源:《农药》 网址: http://www.nyzzs.cn/zonghexinwen/2022/0110/1500.html